Learn how to augment Trino with DuckDB’s AsOf join capabilities to do sequence learning in PyTorch
A simple guide migrating a Poetry and Maturin project to uv
candle
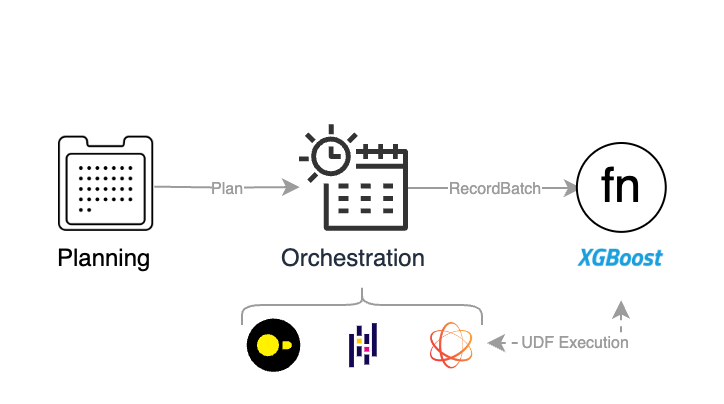
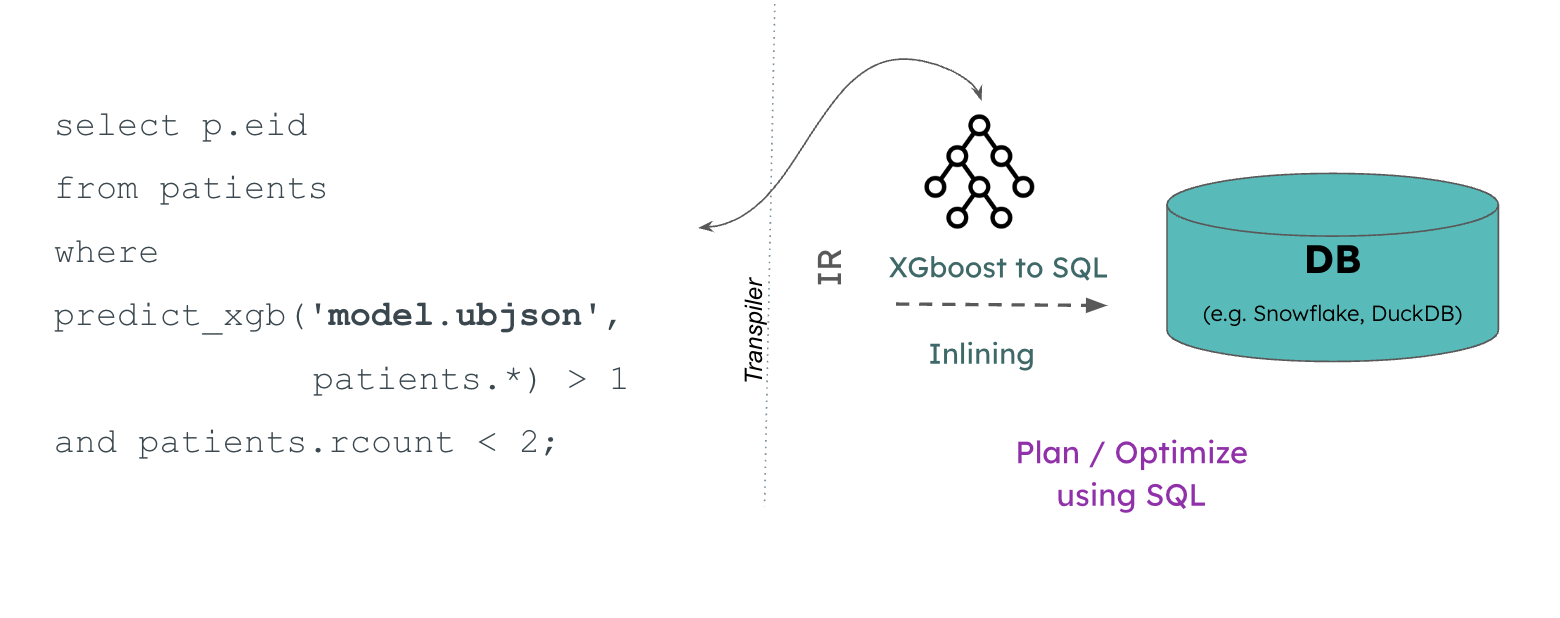
We are previewing a built-in predict UDF for XGBoost. This feature allows to easily score XGBoost models using a performant Rust-based inference engine.
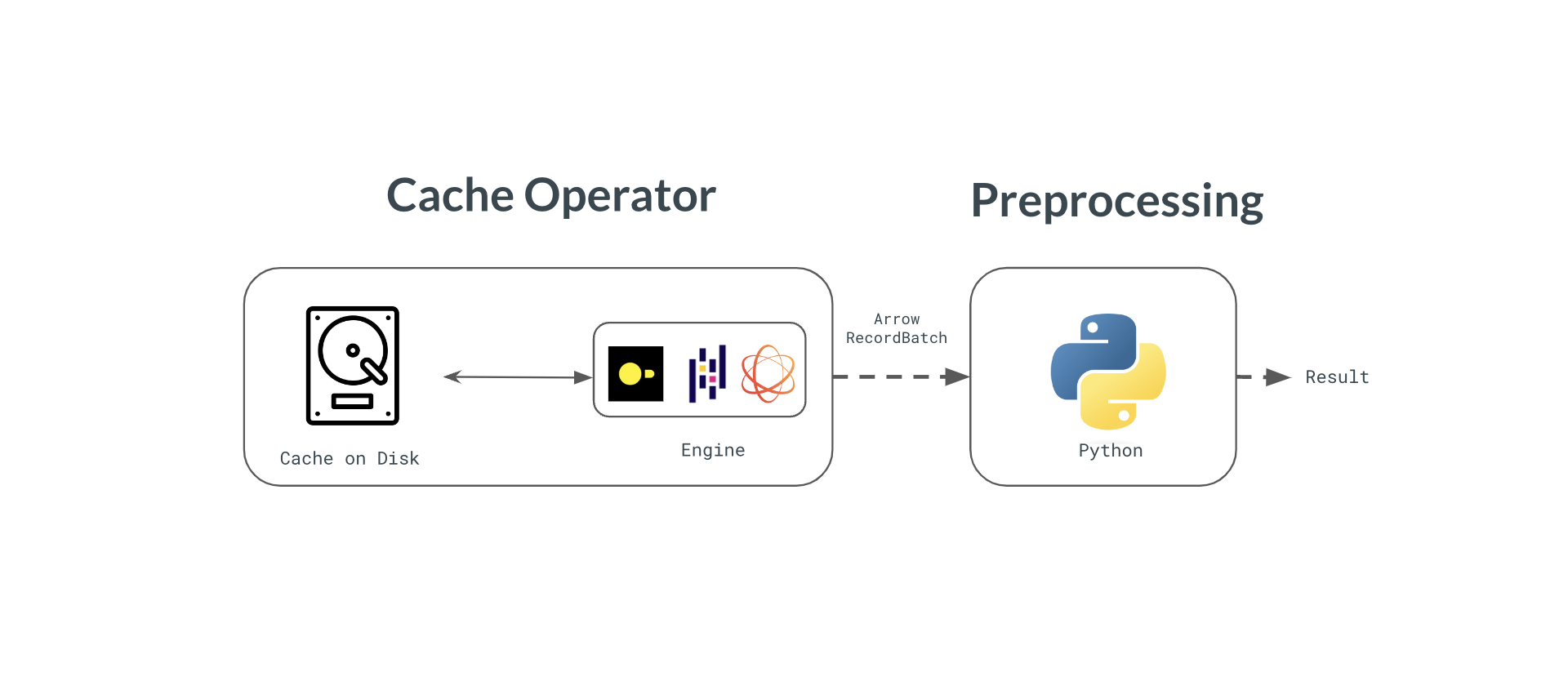
Introducing letsql caching feature for upstream source data. This feature allows you to cache the results of a SQL query in a DataFrame for rapid iteration.
letsql
Demonstration on how to publish to PyPI for Harlequin DataFusion Adapter with Poetry.
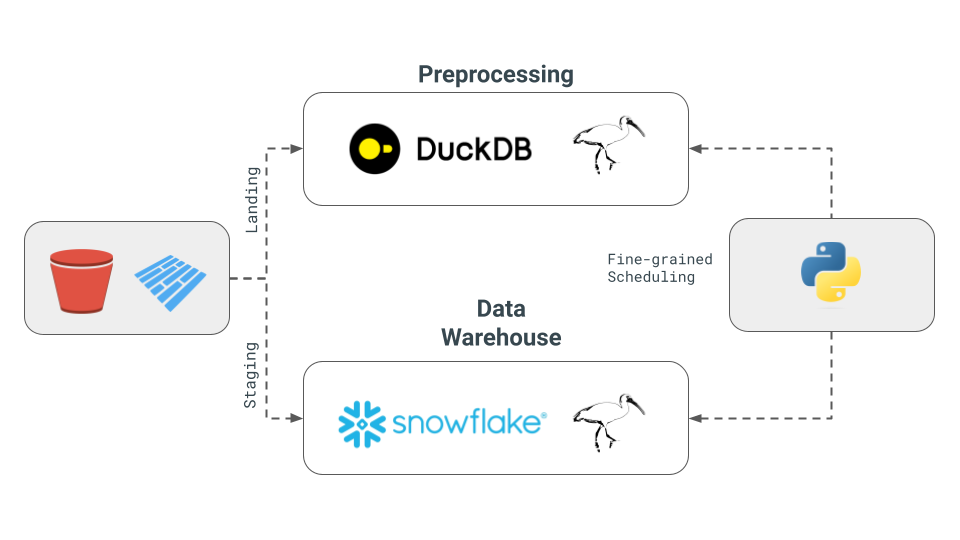
A version of multi-engine data pipeline using python and Ibis instead of dbt and SQL
Demonstration of cross-domain optimization to improve XGBoost model inference
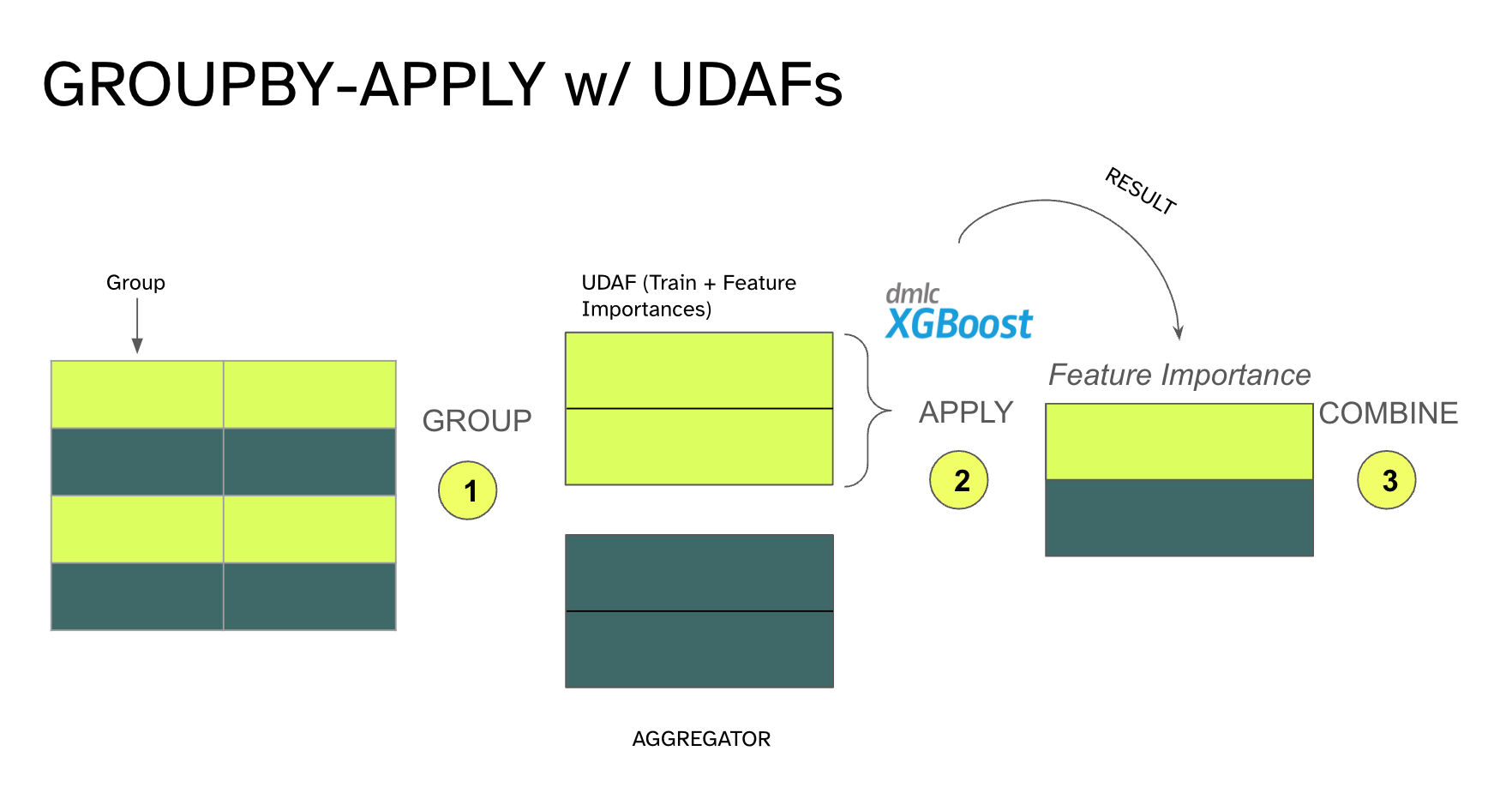
Using DataFusion’s UDAFs to do pandas’s style groupby-apply for XGBoost model training
groupby-apply
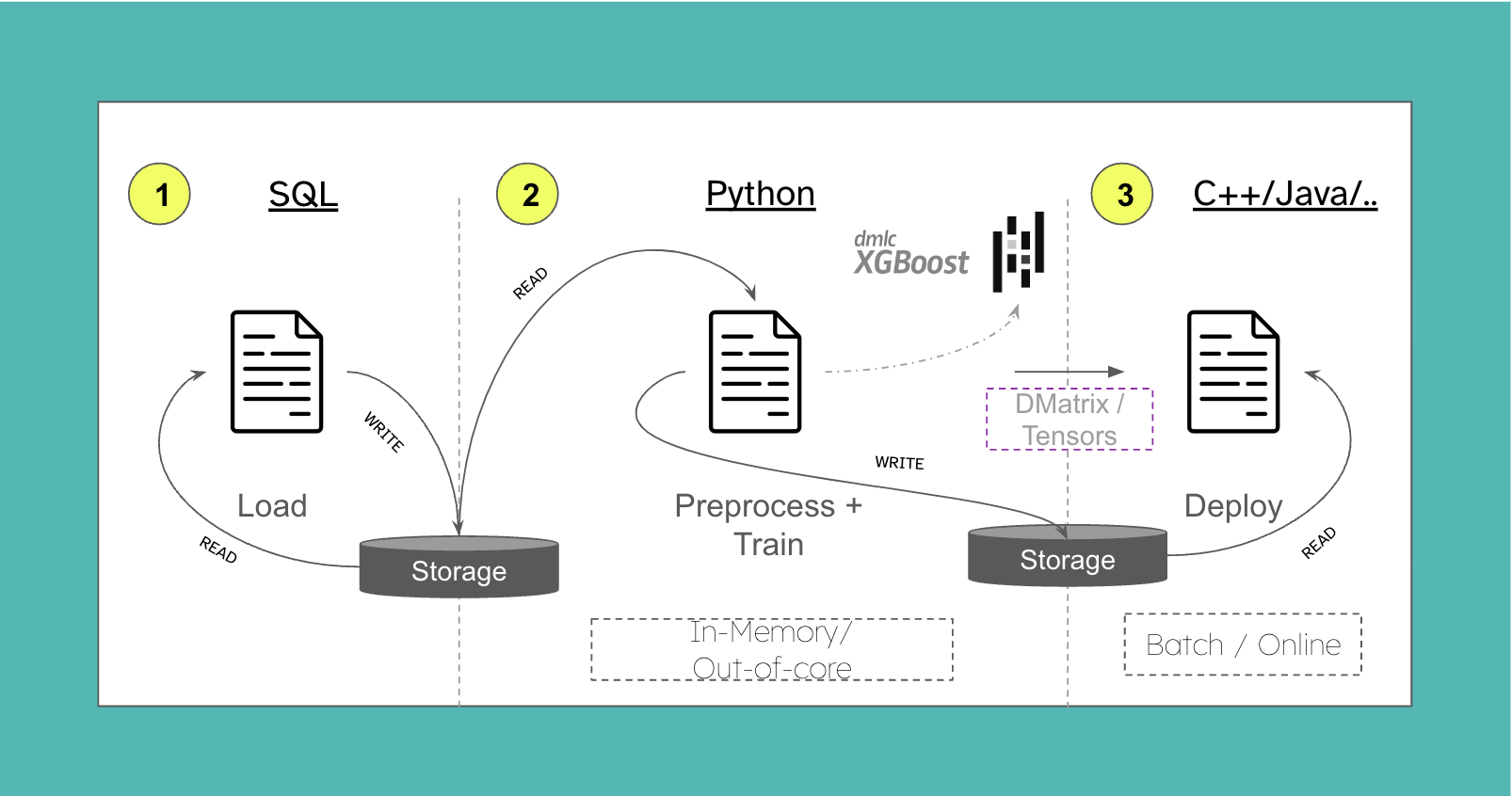
Using DataFusion’s UDFs to create a custom ML scoring pipeline